rlimit: fd - 简明介绍
11 Apr 2022
0. 什么是fd?
FD的全称是 file descriptor 文件描述符。在介绍FD之前,我们先来了解几个问题。
1. 关于fd的几个常见问题
在文件系统中,如果我和你都被允许访问一个文件,我们可以共享文件的数据吗?
答案是:yes。
如果两个进程在同一个文件上读取和写入,它们使用的是同样的文件偏移量吗?
答案是:no。
如果一个进程把同一个文件打开两次,它应该有一个fd还是有两个?在这种情况下,这两个打开共享同一个文件偏移量吗?
答案是:two,no,它们各自拥有自己的文件偏移量。
如果两个线程使用了同一个fd,它们用的是同一个文件偏移量吗?
答案是:yes。
如果一个父进程创造了一个子进程,子进程会继承父进程的fd吗?它们会不会使用同样的文件偏移量?
答案是:yes,yes
2. linux系管理fd时使用的数据结构
先来说明几个事实:
- 当一个进程使用open这个系统调用时,open的返回值是一个小的整数,这个整数被我们称之为fd。
- 每一个进程的fd都是以以下三个fd开始的:
- 标准输入:fd=0
- 标准输出:fd=1
- 标准错误:fd=2
在明确了以上事实后,问题是,我们需要什么样的数据结构(任何人都不会天真的认为仅靠一个小小的整数就可以代表一个fd,它背后肯定是链接着一个文件打开的详细信息)来管理fd?
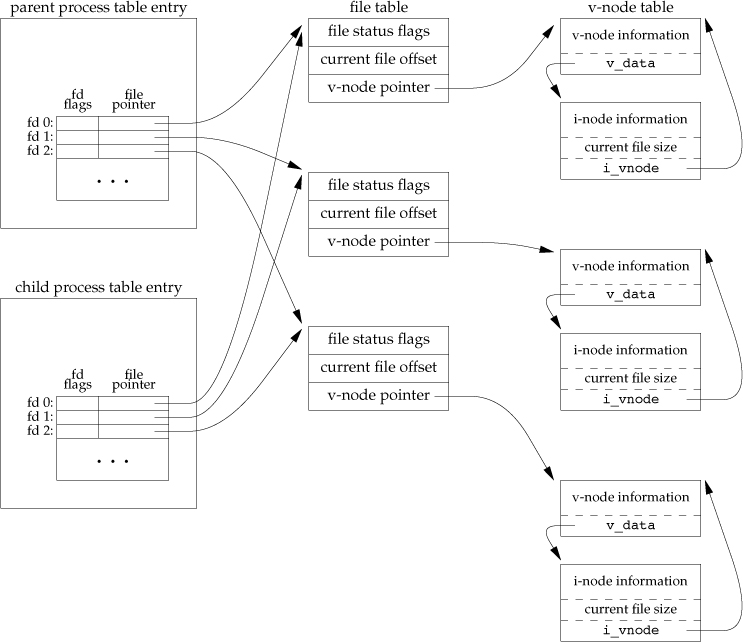
2.1 进程的fd表(进程独享)
每一个进程,拥有一个单独的fd表。举个例子,当一个进程调用open系统调用打开一个文件时,open返回了3这个数字,代表了fd表中的第4个位置(0,1,2,3)。这个fd表同时包含了指向其他数据结构的指针。
问题:我们可以在这个fd表中储存文件偏移量吗?
答案:不可以,因为在*nix系统中,创建进程的方式,是完整的拷贝一个进程的信息成为一个新的进程。如果文件偏移量存在进程的fd表里面,那么意味着新的进程会拥有一个单独的文件偏移量信息,当父进程的文件偏移量变动时,子进程感知不到,因为父子进程是各自独立的fd表。此时,如果我们希望在父子进程中共享文件打开信息时,由于父子进程各自独立的fd表,则无法实现这个目的。所以,更明智的做法是,将文件偏移量储存在另外一个地方,而父子进程的fd表同时来引用同一个文件偏移量,来达到文件信息共享的目的。
2.2 所以,要如何储存文件偏移量呢?
首先,每一个文件偏移量对应着一个open系统调用。所以,我们需要一个数据结构来储存每次open系统调用的结果。它就是文件打开表(file table OR open file table)(所有进程共享)。
文件打开表中储存了如下信息:
- 文件位置(文件偏移量)
- 引用数,当我们有两个或者多个fd引用同一个文件打开对象,需要记录这个数字
- 实际文件对象的引用,实际文件对象储存在内存中的一个数据结构中
2.3 最终,表示实际文件的储存在内存中的数据结构
实际文件对象,我们称之为Vnode(virtual node),是文件在内存中的展现形式。而许许多多的实际文件对象,储存在一个Vnode table(所有进程共享)中。
Vnode table中储存了如下信息:
- 文件元数据的拷贝
- 在磁盘上定位到这个文件的储存块的方式(例如:inode)
3. 总结