数据结构: list&tuple
30 Jul 2015
1. 数据类型内存占用(补充)
1.1 可变对象和不可变对象
简介:python中万物皆对象,变量赋值传递的不是值,而是内存地址。
可变, 就是内容改变,内存地址不变;
不可变,就是内容改变,内存地址肯定会变。
不可变对象:int,string,float,tuple
内容改变,内存地址也改变,说明是不可变对象
>>> num_a = 10 >>> id(num_a) 35986320 >>> num_a = 11 >>> id(num_a) 35986296
num_a--------> 35986320 10 | +-----------> 35986296 11
小整数池(范围[-5,257)之间的数字,为了节省内存)
>>> num_a = 250 >>> num_b = 250 >>> id(num_a),id(num_b),id(250) (35992512, 35992512, 35992512)
num_a ---------->35992512 250
↑
num_b --------------+
超出小整数池范围之外后,相同int也会分配不同内存
>>> num_a = 260 >>> num_b = 260 >>> id(num_a),id(num_b),id(260) (36322176, 36322128, 36322104) num_a ---------> 36322176 260 num_b ---------> 36322128 260
注意这样的变量赋值方式
>>> num_a = num_b = 260 >>> id(num_a),id(num_b),id(260) (36322104, 36322104, 36322128)
num_a ---------->36322104 260
↑
num_b --------------+
num_a和num_b只是获得了同一个内存地址,并不是num_a指向了num_b的地址。
其实小整数池只是python的对象缓冲池中的一个,在python中万物皆对象,而在python的内存缓冲池设计上,又提供了一个对象缓冲池,其他类似于string、tuple等也都有自己相应的缓冲池
其余string、float、tuple不可变对象不再演示
1.2 可变对象:list,dictionary
>>> list_a = ['a', 'b', 'c'] >>> [id(list_a[i]) for i in range(3)] [139949780116744, 139949780116784, 139949780118304]
list_a--------> | 0 | 1 | 2 |
↓ ↓ ↓
| a | b | c |
>>> id(list_a) 139949779418720 >>> list_a.append('d') >>> id(list_a) 139949779418720 # list内容改变后,内存地址并未改变 # dictionary不再演示
1.3 避免低效率的字符串拼接
string+string的拼接方式
>>> list_a = ['g', 'o', 'o', 'd'] >>> str_a = '' >>> for i in list_a: ... str_a += i ... >>> str_a 'good' # 因为string是不可变对象,每一次拼接的时候都要分配一次内存。
推荐使用
>>> list_a = ['g', 'o', 'o', 'd'] >>> str_a = ''.join(list_a) >>> str_a 'good'
2. 补充各类型内存布局
所有对象基于同一个结构
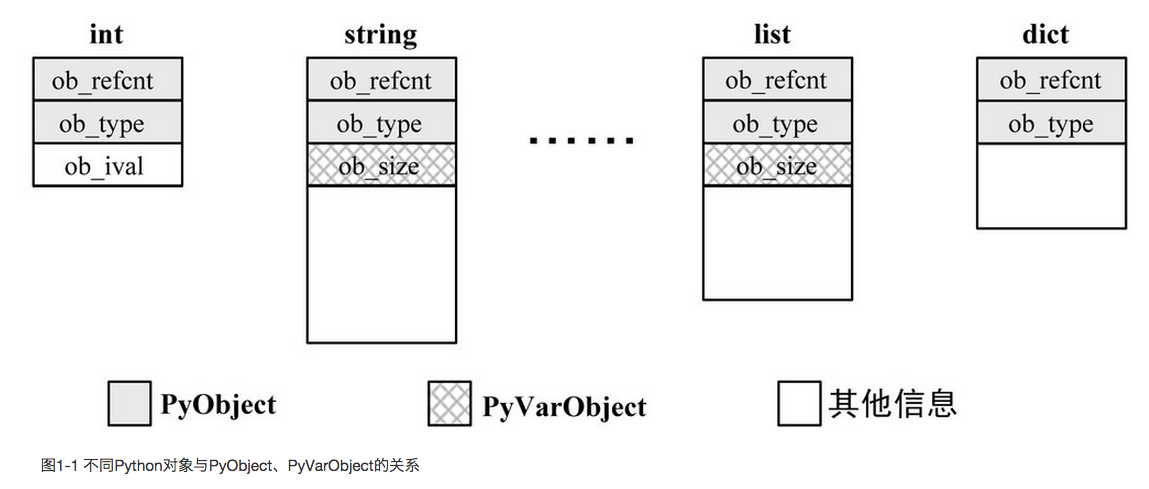
参考:
3. 为什么要有数据结构
- 提供一种方式把元素组织在一起
- 根据不同的需求有了这么四个结构:tuple,list,set,dict
4. tuple元组
4.1 元组的特点
元组不可变
>>> tup_a = (1, 2, 3) >>> id(tup_a) 140262709520176 >>> tup_a = (1, 2, 3) >>> id(tup_a) 140262709520336 # 为何同样内容,tuple的内存地址却不同? # 同样内容,赋值两次改变内存,是因为tuple没有类似于int和string的缓冲池,而int也只有在小整数池中的重复赋值才会保持内存地址不变。 >>> tup_a = tup_a + (4, 5) >>> id(tup_a) 140262710170064
元组中元素可重复
>>> tup_a = (1, 1, 1) >>> tup_a (1, 1, 1)
元组中元素不可更改
>>> tup_a = (1, 1, 1) >>> tup_a[0] = 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
元组可用于迭代
>>> for i in tup_a: ... print i ... 0 1 2 3 4 5 6 7 8 9
4.2 元组的创建及操作
元组的创建
# 用逗号分隔一些值,既可创建元组 >>> 1, 2, 1 (1, 2, 1) # 括号里的值用逗号分隔来创建 >>> tup_a = (1, 2, 1) >>> print tup_a (1, 2, 1) # 空元组的创建 >>> () () # 一个值的元组的创建 >>> (9) 9 # 这只是个数字 >>> (9,) (9,) # 添加逗号就会创建一个值的元组
元组分片
# 获取单个元素 >>> tup_a[1] 1 # 获取元素区间 >>> tup_a[1:3] (1, 2) #tuple[n,m]n代表想获取元素第一个值的index,m是元素区间后的第一个值的index # 获取开始到某个元素,或某个元素到最后 >>> tup_a[:4] (0, 1, 2, 3) >>> tup_a[4:] (4, 5, 6, 7, 8, 9) # 想取最后几个 >>> tup_a[-3:] (7, 8, 9)
4.3 函数
count函数
>>> tup_a = (1, 1, 2, 1) >>> tup_a.count(1) 3
tuple函数
>>> tuple('abc') ('a', 'b', 'c') >>> tuple([1, 2, 3]) (1, 2, 3) >>> tuple((1, 2, 3)) (1, 2, 3)
4.4 元组套元组
>>> tup_a = (1, 2, 3) >>> tup_b = (2, 3, 4) >>> tup = (tup_a, tup_b) >>> tup ((1, 2, 3), (2, 3, 4))
4.5 pack 和 unpack
>>> a, b = 1, 2, 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: too many values to unpack # 变量值和值数量不匹配,无法unpack >>> tup_a = (1, 2, 3) >>> a, b, c = tup_a >>> print a, b, c 1 2 3 # 把变量打包成一个元组,然后解包赋值给三个变量。
4.6 高级用法
问题:t = (i for i in range(10)),t是什么?
>>> t = (i for i in range(10)) >>> t <generator object <genexpr> at 0x7f9174f9e910> # 生成器对象,生成器的内存地址 >>> t.next() 0 >>> for i in t: ... print i ... 2 <------ # 第一个元素不是0,因为我们已经进行过.next()操作,0被拿出来了 3 # 生成器的.next()操作不可逆反 4 5 6 7 8 9
面试必问,实现生成器的三种方式?
5. list的使用
5.1 基础使用
- 切片、创建等操作同tuple
- 增删改查、排序
增加
# append,在最后增加 # L.append(object) -- append object to end >>> t = [1, 2, 3] >>> t.append(4) >>> t [1, 2, 3, 4] # insert,可插入到特定位置 # L.insert(index, object) -- insert object before index >>> t.insert(0,0) >>> t [0, 1, 2, 3, 4]
删除
# remove,按内容删除 # L.remove(value) -- remove first occurrence of value. >>> t [0, 1, 2, 3, 4] >>> t.remove(2) >>> t [0, 1, 3, 4] # pop,按index删除 # L.pop([index]) -> item -- remove and return item at index (default last). >>> t [0, 1, 3, 4] >>> t.pop(2) 3 >>> t [0, 1, 4]
合并
# extend,将list扩展 # L.extend(iterable) -- extend list by appending elements from the iterable >>> t [0, 1, 4] >>> t_ext = [2, 3] >>> t.extend(t_ext) >>> t [0, 1, 4, 2, 3]
查找
# index,返回该index的值 # L.index(value, [start, [stop]]) -> integer -- return first index of value. # 其实就是切片,不演示 # count,返回该值的个数 # L.count(value) -> integer -- return number of occurrences of value >>> t [0, 1, 4, 2, 3, 1, 1, 1] >>> t.count(1) 4
排序
# sort,排列 # L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*; # cmp(x, y) -> -1, 0, 1 >>> t [0, 1, 4, 2, 3, 1, 1, 1] >>> t.sort() >>> t [0, 1, 1, 1, 1, 2, 3, 4] >>> t.sort(reverse=True) >>> t [4, 3, 2, 1, 1, 1, 1, 0] # reverse,逆序排列 >>> t [4, 3, 2, 5, 7, 1, 1, 1, 1, 0] >>> t.reverse() >>> t [0, 1, 1, 1, 1, 7, 5, 2, 3, 4] # 按照index逆序排列 # 用以上操作方法实现LIFO队列(后进先出队列) t = [] t.insert(0, 1) t.insert(0, 2) t.pop(0) -- > 2
5.2 注意事项-这货是引用 ???不理解
>>> t = [1, 2, 3] >>> id(t) 140072509314616 >>> t += [4, 5, 6] >>> id(t) 140072509314616 >>> t = t + [7, 8, 9] >>> id(t) 140072509314760 # 为何t += list等同于t = t + list,却一个换了地址而另一个未换地址? a = [1, 2, 3] id(a) a.append(4) id(a) # 可变对象,内容可以被改变,同时内存地址没变
list内存地址答疑
list使用
t += [...]的方法时address不变>>> t = [1, 2, 3] >>> id(t) 140030583557656 >>> t += [3, 4, 5] >>> id(t) 140030583557656原因是在使用”t += […]“方法时相当于调用了t.extend()方法,而此方法属于原地操作不改变地址。
但是list在正常重新赋值的时候地址会变。
>>> t = t + [6, 7, 8] >>> id(t) 140030583576192
5.3 列表推导式
优点:写起来简便,速度略快(但并不会提高效率)
使用情况:生成不复杂的list时,如果业务复杂尽量不要用,原则是保证可读性
语法example:
[x for x in iterable object][x*y for x in iterable object for y in iterable object][x for x in iterable object if ......]
实例example
>>> result = [] >>> for i in range(10): ... for j in range(10,20): ... result.append(i * j) # 推导式 >>> result_2 = [i*j for i in range(10) for j in range(10,20)] >>> result == result_2 True
5.4 笔试题陷阱
题目: 有个列表t, 去掉偶数位的值
t = [5, 6, 7, 8, 9, 10, 11, 12, 13] for i, v in enumerate(t): if i % 2 == 0: t.remove(v) print t
请问t是什么
推断过程
1)此时i为0,v为5,满足条件,删除5 此时列表更新为[6, 7, 8, 9, 10, 11, 12, 13] 2)此时i为1,v为7,不满足条件 此时列表更新为[6, 7, 8, 9, 10, 11, 12, 13] 3)此时i为2,v为8,满足判断条件,删除8 此时列表更新为[6, 7, 9, 10, 11, 12, 13] 4)此时i为3,v为10,不满足条件 此时列表更新为[6, 7, 9, 10, 11, 12, 13] 5)此时i为4,v为11,满足条件,删除11 此时列表更新为[6, 7, 9, 10, 12, 13] 6)此时i为5,v为13,不满足条件 此时列表更新为[6, 7, 9, 10, 12, 13]
实际过程
>>> t = [5, 6, 7, 8, 9, 10, 11, 12, 13] >>> for i,v in enumerate(t): ... if i % 2 == 0: ... t.remove(v) ... print t ... [6, 7, 8, 9, 10, 11, 12, 13] [6, 7, 8, 9, 10, 11, 12, 13] [6, 7, 9, 10, 11, 12, 13] [6, 7, 9, 10, 11, 12, 13] [6, 7, 9, 10, 12, 13] [6, 7, 9, 10, 12, 13]
6. 扩展: enumerate函数
enumerate(iterable[, start]) -> iterator for index, value of iterable
迭代返回index和value